Friday 30 November 2007
Problems with data transfer between Excel and SPSS
I am having problems with data transfer between excel and SPSS.... It is not an issue of importing the data from excel, that is done without any hitch.. but the 'date' format in excel does not translate very well.... And, when i apply data 'dictionary' it does not fit perfectly to the database in SPSS.. I am in a fix..
Tuesday 10 July 2007
Measuring unmet need for family planning
Preamble
“Millions of women would prefer to avoid becoming pregnant either right away or ever, but are not using contraception. These women have an unmet need for family planning. Programs can serve many of these women by developing strategies that respond directly to their concern.” Ref: Population Reports, Sept 1996. Unmet need is defined on the basis of women’s responses to survey questions and following are some of the definitions that have been used since 1970’s. The KAP-Gap Definition one: Women who wanted to have no more children but were not using contraception. (Ignored spacers, exposure to risk of pregnancy) The world fertility survey (WFS 1972-1984) Definition two: Same as above but excluded pregnant and amenorrheic women, because they did not currently need contraception. (Ignored spacers) In 1981, John Anderson and Leo Morris measured the percentage of women of reproductive age who are “exposed to the risk of unintended pregnancy and are not using contraceptive”. (Included spacers). Next year Nortman and Gary developed a model by including pregnant, breast feeding, or amenorrheic in the definition of unmet need. After ICPD 1994, Sinding and Fathalla have suggested to measure unmet need more broadly including unmet need among people who are using contraception but may be dissatisfied with their method. By using both qualitative and quantitative data, they suggest experience with sideeffects, discontinuation and other problems of contraception could help extend the focus of unmet need from use of any method to the quality of care. Arguments over who is at risk, should we include inappropriate method use and method failure. DHS started asking questions on intentions about current pregnancy, therefore, including pregnant women. Recently included category is unmarried women. In short, include all women who are “at risk” of an unintended or mistimed pregnancy. Considering the importance of measurement of unmet need, now all DHS and FP/RH Survey questionnaire ask about extended definition of unmet need.
Casterline (1997) pointed out that there can be inaccuracies in the reporting of contraceptive use and in the reporting of fertility preferences, and both pieces of information are required for estimating unmet need. Furthermore, his work shows that unmet need is subject to different definitions, and its measurement is not straightforward. Therefore, any survey undertaken for the measurement of unmet need must consider issues of definition in advance.
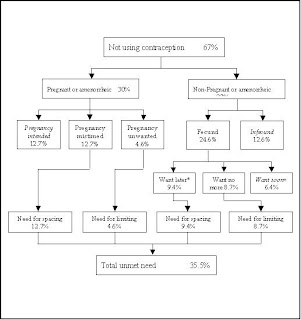
Following chart shows the standard formulation of unmet need.
Chart for calculating unmet need
Preamble
“Millions of women would prefer to avoid becoming pregnant either right away or ever, but are not using contraception. These women have an unmet need for family planning. Programs can serve many of these women by developing strategies that respond directly to their concern.” Ref: Population Reports, Sept 1996. Unmet need is defined on the basis of women’s responses to survey questions and following are some of the definitions that have been used since 1970’s. The KAP-Gap Definition one: Women who wanted to have no more children but were not using contraception. (Ignored spacers, exposure to risk of pregnancy) The world fertility survey (WFS 1972-1984) Definition two: Same as above but excluded pregnant and amenorrheic women, because they did not currently need contraception. (Ignored spacers) In 1981, John Anderson and Leo Morris measured the percentage of women of reproductive age who are “exposed to the risk of unintended pregnancy and are not using contraceptive”. (Included spacers). Next year Nortman and Gary developed a model by including pregnant, breast feeding, or amenorrheic in the definition of unmet need. After ICPD 1994, Sinding and Fathalla have suggested to measure unmet need more broadly including unmet need among people who are using contraception but may be dissatisfied with their method. By using both qualitative and quantitative data, they suggest experience with sideeffects, discontinuation and other problems of contraception could help extend the focus of unmet need from use of any method to the quality of care. Arguments over who is at risk, should we include inappropriate method use and method failure. DHS started asking questions on intentions about current pregnancy, therefore, including pregnant women. Recently included category is unmarried women. In short, include all women who are “at risk” of an unintended or mistimed pregnancy. Considering the importance of measurement of unmet need, now all DHS and FP/RH Survey questionnaire ask about extended definition of unmet need.
Casterline (1997) pointed out that there can be inaccuracies in the reporting of contraceptive use and in the reporting of fertility preferences, and both pieces of information are required for estimating unmet need. Furthermore, his work shows that unmet need is subject to different definitions, and its measurement is not straightforward. Therefore, any survey undertaken for the measurement of unmet need must consider issues of definition in advance.
Following chart shows the standard formulation of unmet need.
Wednesday 7 March 2007
Aggregate
Well, why do we need this command... Basically to collaspe a data file on the basis of one or some variables!! So, in other words if you have an individual level file, and you have community or household information in that file, you can AGGREGATE that file into a household/community file by using the id variables, and of course some common sense/research questions in selecting how to collapse the individual level characteristics on a bigger level.. What makes sense!!!
Aggregate helps perform some mathmetical functions on variables, for all the records, at an aggregate level. for example, you cannot use syntex to ADD all the beds given in a numeric variable called BEDS, for all CASES. Nor can you pick mean, median, max, min etc. values, just across all the CASES!! So, if you understand this concept you can go ahead and perform the AGGREGATE commad on your data file. I NEED AN EXPERT TO GIVE MORE DETAILS!!!
Here is the syntex:
****the vars used in BREAK get included automatically in the outfile'***.
1) Get the file to aggregate
2) give command:
AGGREGATE
/OUTFILE='NEW FILE NAME WITH PATH.sav'
/BREAK= INDEX VARIABLES
/VAR1 OR NEWLY ASSIGNED NAME*=FIRST (VAR1)
/VAR2 =MAX (VAR2)
/VAR3 =LAST (VAR3)
/VAR4 =MIN (VAR4)
/VAR5 =SD (VAR5)
/VAR6 =SUM (VAR6)
/VAR7 =MEAN (VAR7)
/VAR8 =MEDIAN (VAR8).
* for all variables
**It is obvious that the mathmatical functions make sense only for continous variables, for catagorical variable use first, last, min, and max.
3) Get the new file.
Aggregate helps perform some mathmetical functions on variables, for all the records, at an aggregate level. for example, you cannot use syntex to ADD all the beds given in a numeric variable called BEDS, for all CASES. Nor can you pick mean, median, max, min etc. values, just across all the CASES!! So, if you understand this concept you can go ahead and perform the AGGREGATE commad on your data file. I NEED AN EXPERT TO GIVE MORE DETAILS!!!
Here is the syntex:
****the vars used in BREAK get included automatically in the outfile'***.
1) Get the file to aggregate
2) give command:
AGGREGATE
/OUTFILE='NEW FILE NAME WITH PATH.sav'
/BREAK= INDEX VARIABLES
/VAR1 OR NEWLY ASSIGNED NAME*=FIRST (VAR1)
/VAR2 =MAX (VAR2)
/VAR3 =LAST (VAR3)
/VAR4 =MIN (VAR4)
/VAR5 =SD (VAR5)
/VAR6 =SUM (VAR6)
/VAR7 =MEAN (VAR7)
/VAR8 =MEDIAN (VAR8).
* for all variables
**It is obvious that the mathmatical functions make sense only for continous variables, for catagorical variable use first, last, min, and max.
3) Get the new file.
Tuesday 6 March 2007
Joining two files
There are two concepts of joining files in databases, either you join the columns (variables) or the rows (cases). I will give the formula for the former.
First of all, to match two files with different variables, it is imperative to have one common variable in the files.
1) Sort the files to be matched on the basis of index variable.
SORT CASES BY variable_name.
2) save the sorted files.
3) The join command in SPSS syntax:
MATCH FILES
/FILE ='FILE_A_NAME_WITH_PATH.sav'
/FILE ='FILE_B_NAME_WITH_PATH.sav'
/BY index variable(s).
ANOTHER NOTE: I think we should TURN OFF Weights before this command.
**If one of the files has different unit of analysis, for example a household file, or a community file and the other is a individual level file, then the household/community file should be written like the following:
/TABLE ='FILE_A_NAME_WITH_PATH.sav'
** If one of the data files is already open in the SPSS, then only a asterik can be used instead of full path and file name:
/TABLE=*
OR
/FILE=*
4) the resultant file is a new matched file, save with a new name.
Important Note:
If the files to be matched have variables with similar names but different information, such as FileA may have q9 which is respondent's residency status, while FileB also has q9 which is about No. of courses they are taking. The file match command would choose the first files values only without giving you a choice. In order to deal with the problem, you can utilize the RENAME variable sub-command option:
You can rename the variables in the MATCH FILES command (which renames the variables before doing the matching). This allows you to select variable names that do not conflict with each other, as illustrated below.
TIPS:
****GET THE FILES AND DROP USELESS VARS****.
***FIRST SORT THE FILES TO MATCH ****.
**** IF REQ. SAVE AS NEW FILES****.
First of all, to match two files with different variables, it is imperative to have one common variable in the files.
1) Sort the files to be matched on the basis of index variable.
SORT CASES BY variable_name.
2) save the sorted files.
3) The join command in SPSS syntax:
MATCH FILES
/FILE ='FILE_A_NAME_WITH_PATH.sav'
/FILE ='FILE_B_NAME_WITH_PATH.sav'
/BY index variable(s).
ANOTHER NOTE: I think we should TURN OFF Weights before this command.
**If one of the files has different unit of analysis, for example a household file, or a community file and the other is a individual level file, then the household/community file should be written like the following:
/TABLE ='FILE_A_NAME_WITH_PATH.sav'
** If one of the data files is already open in the SPSS, then only a asterik can be used instead of full path and file name:
/TABLE=*
OR
/FILE=*
4) the resultant file is a new matched file, save with a new name.
Important Note:
If the files to be matched have variables with similar names but different information, such as FileA may have q9 which is respondent's residency status, while FileB also has q9 which is about No. of courses they are taking. The file match command would choose the first files values only without giving you a choice. In order to deal with the problem, you can utilize the RENAME variable sub-command option:
You can rename the variables in the MATCH FILES command (which renames the variables before doing the matching). This allows you to select variable names that do not conflict with each other, as illustrated below.
(Source: http://www.ats.ucla.edu/stat/spss/modules/merge.htm)MATCH FILES FILE="FILEA.sav" /RENAME=(inc98 = dadinc98)
/FILE="FILEB.sav" /RENAME=(inc96 inc97 inc98 = faminc96 faminc97 faminc98)
/BY id.
TIPS:
****GET THE FILES AND DROP USELESS VARS****.
***FIRST SORT THE FILES TO MATCH ****.
**** IF REQ. SAVE AS NEW FILES****.
Calculate age from survey data
The calculation of age from survey data may be as following:
AGE MONTHS=(Data of survey-Date of birth)/30.42)
where 30.42 is the average month length all over the year.
or
AGEYEARS=((Date of survey or interview-Date of birth)/365.25)
You should have the two dates (date of survey and date of birth) in NUMERIC format.
You also can use the option of integer in the beginning of the formula if you want the results to be in integer months or years (no fractions).
Tuesday 30 January 2007
The purpose of this blog
well, i have had many frustrations with spss syntax because it is not easy to remember each and everything if you don't use the commands for a very long time... there are many ways to save the commands and i did do that.. but they are not organized and sometimes can't find them due to various reasons.. the solution? blog them!!!!
Subscribe to:
Posts (Atom)